
AI Assist: A SQL copilot for SQL lovers
Goals
Help analysts at all experience levels write SQL more efficiently
Reduce time spent on repetitive edits
Ensure trust by keeping a human in the loop
Focus areas
User research, prototyping
UX and UI design
Project and product management
Marketing video design
AI Assist started as “FlexQL”, an internal hackathon project focused on leveraging LLMs and text-to-SQL workflows.
Our team decided to prioritize Mode’s core audience: SQL-savvy analysts. By narrowing the scope, we quickly honed in on a solution that focused on translating natural language into valid SQL, assuming users already understood what data they wanted to query. Our prototype, “FlexQL,” won Best in Show and Hacker’s Choice.


Our goal was to make SQL writing faster and more efficient for analysts at all experience levels. But instead of building another AI chatbot, we decided to integrate natural language directly into the SQL writing process.
With FlexQL, analysts could add English phrases to SQL as “pseudo code.” AI translated the phrases into valid SQL syntax. The result was a seamless blend of manual SQL writing and AI-driven enhancements. For the hackathon proof-of-concept, I focussed on:
allowing users to opt-in to AI-augmented query writing
providing users with a way to visually distinguish their natural language comments from standard SQL
introducing methods to verify AI-generated syntax
Despite growing momentum to ride the generative AI wave, stakeholders weren’t convinced that FlexQL would resonate with our customers (specifically more advanced analysts) and worried there wasn’t a clear path to evolving the UX.
To de-risk the project, I conducted customer research to better understand how analysts were working with ChatGPT already, and how they felt AI could make their jobs easier.

Research revealed that analysts spent significant time revising repetitive SQL. They were hopeful AI could expedite these edits, enabling them to focus on higher-value work.
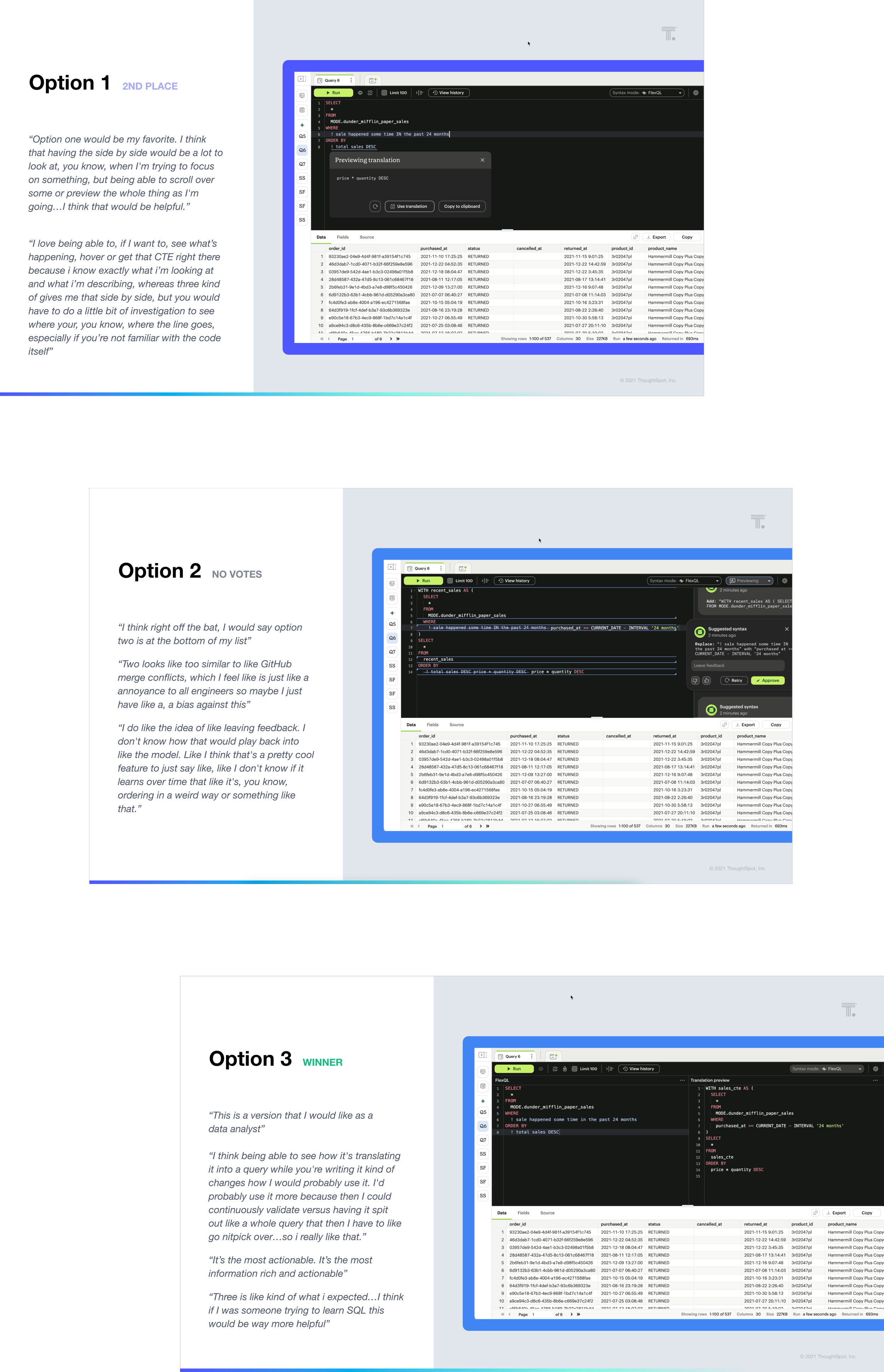
In addition to validating the problem I also did perception testing on the UX, offering up a few different mental models:
AI as on-demand snippets:
embed English phrases as variable-like placeholders for SQL logicAI as a collaborative reviewer:
suggest SQL revisions similar to tracking changes in Google DocsAI as a side-by-side edit mode (chosen):
allow users to compare AI output with their edits before accepting changes
The results highlighted a strong interest in side-by-side interfaces for comparing AI-generated and manually written SQL. Analysts valued this as both a validation tool and a learning resource for more novice writers.
Following the research and shortly after Mode’s acquisition by ThoughtSpot, the project was officially green-lit.
We were given an ambitious deadline to try and soft launch the MVP by. To help align the team, I led cross-functional sessions to:
review the original proof of concept
propose and prioritize changes based on the research insights
align engineering and design efforts
I also dove into the world of prompt engineering, as we uncovered how to leverage OpenAI’s API to generate SQL and what meta-data we’d need to pass along.
Though I typically work closely with engineering partners, we collaborated nonstop throughout this effort. Agile cycles, quick feedback loops, and iterative dogfooding shaped our MVP while ensuring it would meet customer needs.

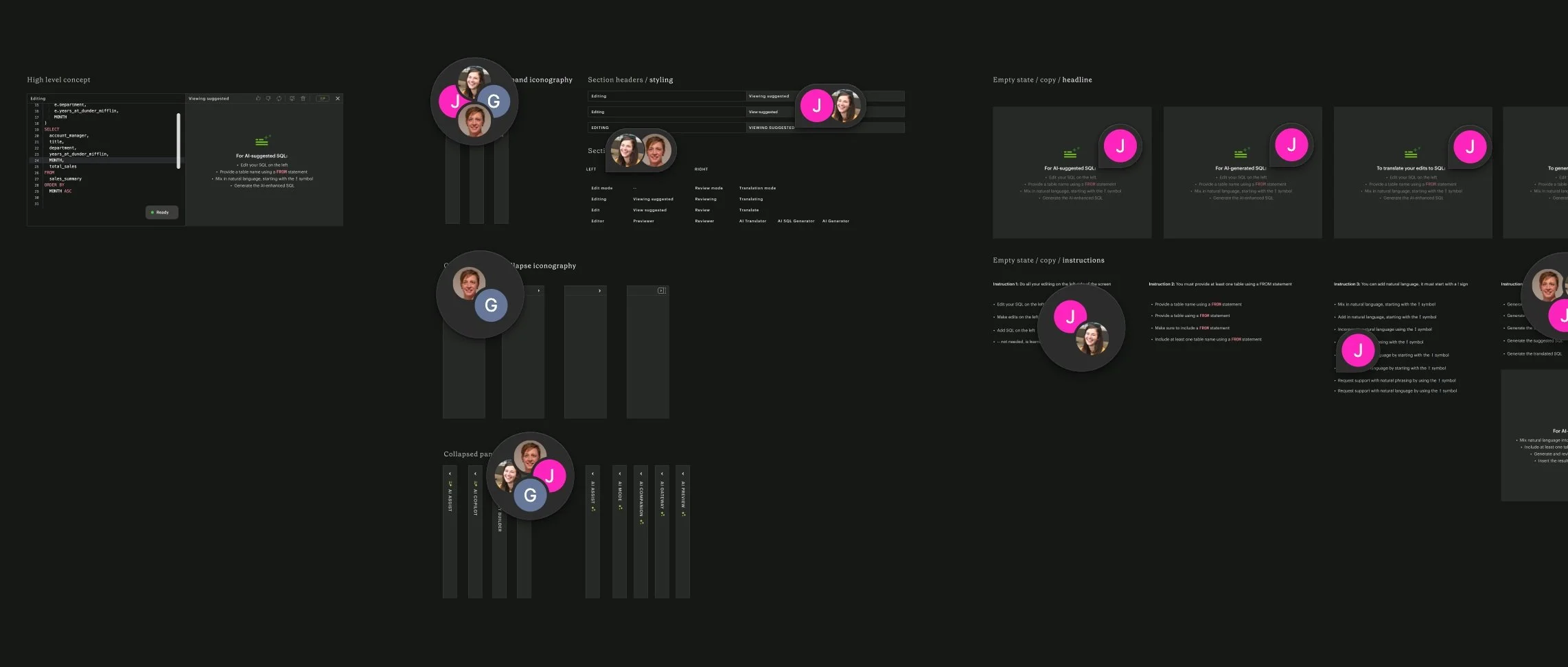
I conducted usability testing on our MVP, uncovering a few key enhancements and prompt fixes before the launch.
FlexQL was ultimately renamed to AI Assist, and launched on schedule with:
An improved side-by-side editor:
comparison of AI and user-generated SQL before runningEnhanced syntax support:
more visual clarity and autocomplete affordances for starting a natural language commandFeedback mechanisms:
affordances for users to rate AI output and add comments to refine the featureContextual prompt suggestions:
access to supported use cases, inspired by user testing
Sorry for the long windedness. I'm just really excited about this. The second I got the email I was in here using Al Assist as fast as humanly possible. So far I'm really enjoying it, and I just wanted to share that feedback.
Early adopter & tester


